Using Selenium in Python
Learning Selenium through an example
Today we are going to learn how to automate your browser using Selenium in Python.Today we will go to Youtube search something and store the results as JSON.Scraping Youtube results is not possible using normal webscraping as it uses a JS framework.
Requirements
For web scraping we would require selenium library.
Just install it with pip as:
pip3 install selenium
You would also require chromedriver if you have Chrome or geckodriver if you have Firefox.
Starting
Firstly, we would need to import the required libraries:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import os
import json
from time import sleep
Now, we would need to provide the path for our chromedriver or geckodriver.(NOTE:I have kept the chromedriver in the same directory as my python script.)
In python in Windows this would look like:
driver=webdriver.Chrome(os.getcwd()+"/chromedriver.exe")
For Firefox:
driver=webdriver.Firefox(os.getcwd()+"/geckodriver.exe")
We will now navigate to the youtube website.
url="https://www.youtube.com/"
driver.get(url)
Now the browser will go to youtube.com .
Searching a video
The best way in my opinion to learn selenium is running it in interactive mode.So through command line navigate to where your script is and run:
python3 -i your_file_name.py
You will see that a browser has opened and it has navigated to youtube.com.
Next we need to get the serach bar, we do this by clicking inspect element on it.

From this photo we can see that it is an input element id search. We get that element using selenium:
search=driver.find_element_by_xpath("//input[@id='search']")
Now we send what we want to type:
search.send_keys("foo bar")
As you can see foo bar is typed in the search bar.Now sending enter to search:
search.send_keys(Keys.RETURN)
Now it should have opened the results page.
Storing it as JSON
We now need to store the title and links of videos so we first inspect element the title to find which element they are in.
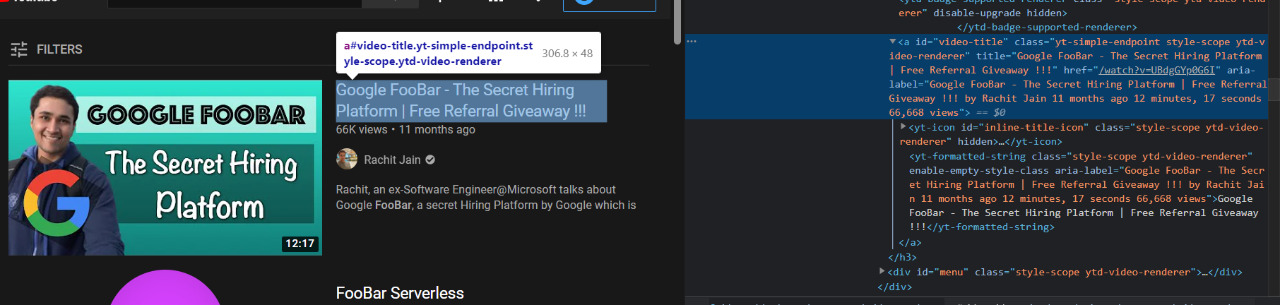
We see that they are in an a element with id = video-title. So we just find all of these and store the href and title in a list.
videos=driver.find_elements_by_xpath("//a[@id='video-title']")
ResultList=[]
for video in videos:
ResultDict={}
ResultDict["title"]=video.get_attribute("title")
ResultDict["link"]=video.get_Attribute("href")
ResultList.append(ResultDict)
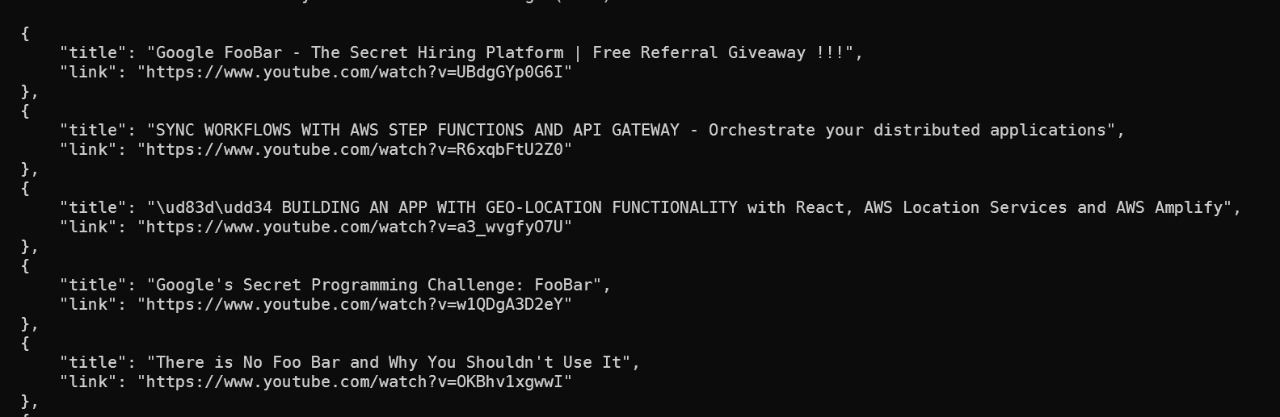
print(json.dumps(ResultList,indent=4))
Output:
Entire Code
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import os
import json
from time import sleep
driver=webdriver.Chrome(os.getcwd()+"/chromedriver.exe")
url="https://www.youtube.com/"
driver.get(url)
search=driver.find_element_by_xpath("//input[@id='search']")
search.send_keys("foo bar")
sleep(1)#waiting for the text to be typed
search.send_keys(Keys.RETURN)
sleep(2)# to give time for the search to load
videos=driver.find_elements_by_xpath("//a[@id='video-title']")
ResultList=[]
for video in videos:
ResultDict={}
ResultDict["title"]=video.get_attribute("title")
ResultDict["link"]=video.get_attribute("href")
ResultList.append(ResultDict)
print(json.dumps(ResultList,indent=4))
driver.quit()#closing the browser
Conclusion
This is just a small part of what selenium can do, read more here. Have fun experimenting with this!